En producción en minutos. Compatible con cualquier SDK de OpenAI. Crea una API key en la consola, cambia una línea y ya estás corriendo modelos open en infraestructura europea.
Control cuando lo necesitas. Simplicidad cuando la quieres.
La IA ya es infraestructura estratégica. Con Helmcode te olvidas de operar la infraestructura porque nosotros lo hacemos por ti. Tú despliega y usa modelos. Nosotros nos ocupamos del resto.
Operación
Operamos el stack. Tú haces producto.
Infraestructura de IA privada significa GPUs, vLLM, escalado, observabilidad y actualizaciones. Nos encargamos de todo. Olvídate de contratar perfiles de infraestructura de IA que no existen en el mercado.
Coste
De factura variable a tarifa plana.
Las APIs comerciales van bien para arrancar. Cuando el uso crece, la factura crece con él. Helmcode lo convierte en una tarifa plana mensual. La IA a escala deja de ser un problema de presupuesto.
Soberanía
Datos y modelos en Europa.
Control sobre tus datos. Control sobre tus modelos. Control sobre tu infraestructura. Sin logs y procesado solo en la UE, fuera del alcance del Cloud Act. Cumplimos con GDPR, AI Act y DORA por cómo está construida la plataforma.
// inferencia gestionada
El equipo despliega. De las GPUs nos encargamos nosotros.
Esto es lo que significa inferencia gestionada. Aprovisionamos, monitorizamos y operamos todo el stack para que tu equipo se centre en el producto, no en mantener GPUs.
Los modelos open cubren el 80% de los casos de uso en empresa: RAG, clasificación, generación de código, asistentes internos. El 20% donde necesitas GPT-5 es mucho más estrecho de lo que parece.
$250en 9 días
Caso real
GitHub pasó Copilot de tarifa plana ($19/mes por usuario) a facturación por token. Un solo developer puede generar $250 de factura en 9 días. Los mismos flujos, otro modelo de precio.
Inferencia privada. Compliant desde el diseño. Rápida por defecto.
Tokens ilimitados en infraestructura europea. Lista para el AI Act, nativa en GDPR. El equipo despliega sin esperar a legal, seguridad ni DevOps.
01
Tokens ilimitados
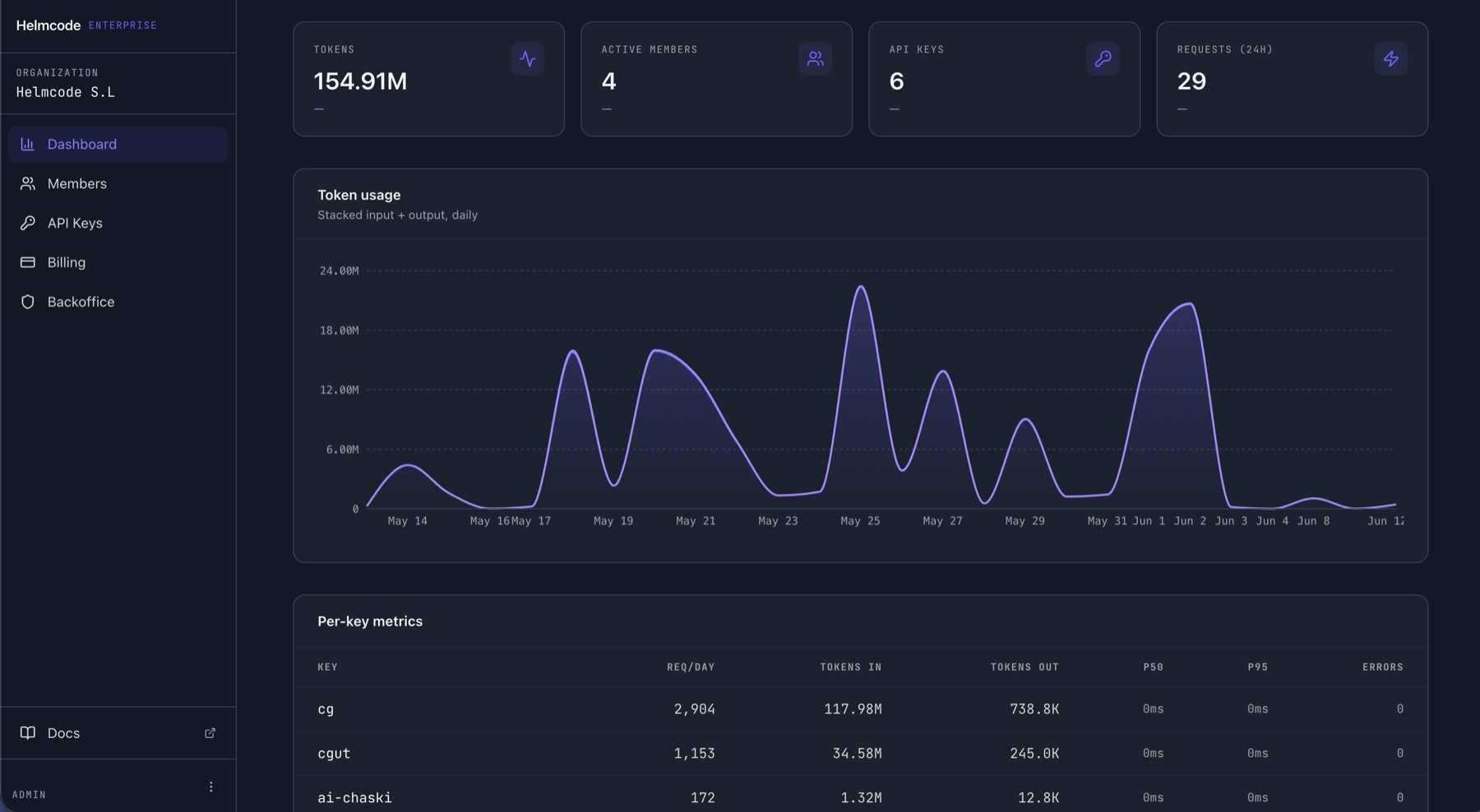
Sin límite de consumo. Los rate limits van por API key — RPM y concurrencia — no por tokens totales. Una sola key puede procesar 500M tokens en menos de 24 horas.
02
Nativo en AI Act
Los prompts nunca se almacenan. El código nunca entrena un modelo. Los datos se procesan solo en la UE, fuera de infraestructura de hyperscalers sujeta al Cloud Act.
03
Reemplazo directo de OpenAI
Basta con cambiar la base URL y la API key. Cualquier cliente compatible con OpenAI funciona tal cual — Cursor, Zed, OpenCode, Hermes, cualquier SDK. El código existente corre sin cambios.
04
Modelos open en la frontera
DeepSeek V4-Flash, Qwen 3.6, Gemma 4. Más embeddings, reranking, TTS y STT. El stack de inferencia completo, no solo completado de texto.
05
Infraestructura gestionada y dedicada
NVIDIA B200. 192GB VRAM. 256GB DDR5 RAM. La provisionamos, monitorizamos y actualizamos. Nadie del equipo toca una GPU.
06
SLA enterprise
99.9% de uptime en Scale y superiores. Monitorización continua, soporte prioritario y penalizaciones contractuales si no lo cumplimos.
// modelos
Nueve modelos. Una sola API.
De razonamiento con contexto largo a voz en tiempo real — el stack de inferencia open completo, listo para producción en infraestructura europea.
Nuestro flagship para trabajo complejo y agéntico — documentos largos, codebases profundas y uso de herramientas multi-paso. Razonamiento paso a paso nativo y tool calling con ventana de 1M tokens.
mimo-v2.5flagship310B MoE · 1M contexto
Entrada multimodal completa en un solo modelo: visión, audio y texto. Entiende imágenes, transcribe audio y razona sobre medios mixtos sin cambiar de proveedor.
qwen3.635B MoE · 256K contexto
El caballo de batalla en throughput. Decodificación especulativa para 2× velocidad más tool calling — ideal para RAG de alto volumen, clasificación y autocompletado de código.
gemma426B MoE · 256K contexto
La arquitectura abierta de Google con visión y razonamiento. Eficiente y capaz para asistentes del día a día y trabajo con documentos.
Embeddings y Reranking
ModeloPara qué sirve
qwen3-embedding8B · 4096 dimensiones
Embeddings semánticos multilingües en 100+ idiomas. MMTEB 70.58 — la capa de recuperación de tus pipelines RAG.
Rererank8B · Qwen3 Reranker
Reranking semántico cross-lingual. Reordena los pasajes recuperados por relevancia real para afinar los resultados de RAG.
Voz
ModeloPara qué sirve
Kokokoro82M parámetros · 67 voces
Texto a voz en tiempo real con latencia sub-segundo. 67 voces, español incluido — rápido para agentes en vivo e IVR.
whisper-large-v399+ idiomas
Voz a texto de última generación. 3,2% WER en español, hasta 25MB / ~2 min de audio por petición.
Los IDs de modelo van tal cual — se copian directamente en el código.
// enterprise
Tres modelos de despliegue. Un solo stack de inferencia.
Mismo stack. Misma API. Mismo código. Lo que cambia es el nivel de soberanía.
Shared
Infraestructura compartida en la UE.
La vía más rápida a inferencia privada en producción. Cluster gestionado en la UE, sin logs y nativo en GDPR — sin provisionar una sola GPU.
·Desde 399€/mes
·Setup en minutos
·Sin logs · Datos en la UE
·SLA 99,5% en Growth
Dedicated
Hardware Blackwell exclusivo.
NVIDIA Blackwell reservado en exclusiva dentro de la infraestructura europea de Helmcode. Throughput garantizado, aislamiento de red completo y modelos custom.
·NVIDIA B200
·Modelos custom y fine-tuning
·Aislamiento de red completo
·SLA a medida
On-premise
En tu datacenter.
Desplegamos y operamos todo el stack de inferencia dentro del datacenter del cliente — o en uno de nuestros partners. Los datos no se mueven. Ni un solo token sale de la red.
·Tu datacenter o el nuestro
·Despliegue llave en mano
·Sin movimiento de datos
·SLA y soporte a medida
Preparado para banca, salud, defensa y sector público.
// empezar
EMPIEZA A QUEMAR TOKENS
Olvídate de la infra de IA. Despliega hoy el primer endpoint de inferencia privada.
Tarifa plana. Datos en la UE. Compatible con la API de OpenAI.
Lo que preguntan los equipos de ingeniería y legal antes de mover la inferencia in-house.
¿Cómo migro desde OpenAI o Anthropic?
Cambias la base URL y la API key, nada más. Cualquier SDK o herramienta compatible con OpenAI funciona sin tocar código: Cursor, Zed, OpenCode, clientes propios. La mayoría de equipos están en producción el mismo día.
¿Dónde se procesan los datos? ¿Guardáis los prompts?
Solo en infraestructura de la UE — nunca en hyperscalers estadounidenses sujetos al Cloud Act. Los prompts no se almacenan nunca. Cumplimos GDPR y AI Act desde la arquitectura, no desde la configuración.
¿Qué significa de verdad "tokens ilimitados"?
No hay límite de consumo total. Los rate limits van por API key — peticiones por minuto y concurrencia — no por tokens procesados. Una sola key mueve cientos de millones de tokens al mes.
¿Qué modelos puedo correr? ¿Puedo traer el mío?
DeepSeek V4-Flash, MiMo, Qwen 3.6 y Gemma 4, más embeddings, reranking, TTS y STT. En Dedicated y On-premise también se pueden correr modelos custom o fine-tuned.
¿Cómo funciona el precio?
Tarifa plana mensual por API key, no por token. Desde 399€/mes, sin sorpresas de consumo ni permanencia. Una línea fija en la cuenta de resultados.
¿Y los SLA y el despliegue on-premise?
99,9% de uptime en Scale y superiores, con penalizaciones contractuales si no lo cumplimos. Para compliance estricto, desplegamos y operamos todo el stack de inferencia dentro del datacenter del cliente — ni un solo token sale de la red.
// cookies
Usamos cookies estrictamente necesarias para que el sitio funcione y, solo con consentimiento explícito, Google Analytics para entender el uso. Nada de publicidad, nunca — consulta la Política de cookies.
// preferencias
Estrictamente necesariasNecesarias para que el sitio funcione y sea seguro.